- 软件大小:2.24MB
- 软件语言:简体中文
- 软件类型:国产软件
- 软件类别:字体素材
- 更新时间:2019-03-08
- 软件授权:免费版
- 官方网站://www.9553.com
- 运行环境:XP/Win7/Win8/Win10
- 标签:字体素材 义启春芽字体
3.34MB/简体中文/7.5
92KB/简体中文/7.5
2.06MB/简体中文/7.5
980KB/简体中文/7.5
7.70MB/简体中文/7.5
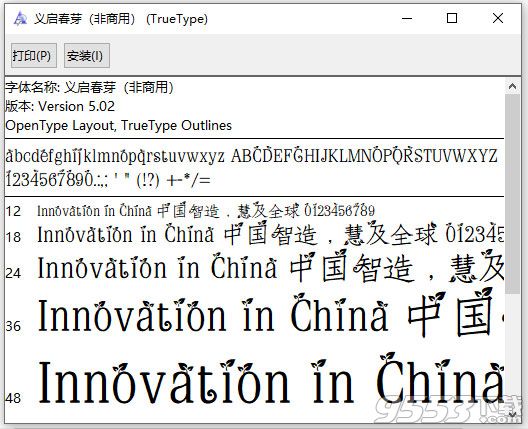
义启春芽字体是一款作用在Windows电脑系统上的字体文件,这款文件的粗细适中,看着也很清楚,整体偏细长,而且在文字的上方还时不时长出几颗嫩芽,非常有意思,有喜欢的朋友欢迎下载。
步骤一:字体库安装到计算机系统中,任何桌面程序的字体栏菜单都可以调用并在屏幕显示。
步骤二:Windows系统:将字体文件复制到C:WINDOWSFonts 文件夹即可(Win7以上版本选中文件,右键可以直接安装)。步骤三:MAC OS系统:点击菜单栏—>前往—>应用程序—>字体册,将字体文件复制到字体册中即可。
本站所有字体资源仅供个人学习与参考,如需商业使用请到相关官网授权。
1.为什么在安装时会出现"文件损坏"?
答:这是因为字库与您的系统产生冲突(特别是xp系统,因为有很多字体以前都是在win98或更早的版本下开发的。)
2.为什么安装完字体后我在使用时找不到?
答:有些字体:例如华康系列的。他们在列表显示为他的相关拼音代码,您可以在下载回来时双击字体可以看到这个字体的名字是什么。然后在选择使用这个字体时,就请选他的拼音字,就是您要的字体了。
3.为什么有些字体的字打不出来?
答:有些字库必须要在繁体输入的情况下才能打出来的。(例如金梅字库等),如果使用繁体输入法输入的文字依然无法出来,可能是字体的字库不全,是没办法打字这个字的。
井柏然字体软件 v1.0
3.27MB/简体中文/8.2详情
方正正黑系列字体下载
5.85MB/简体中文/4.5详情
苹方字体(ios9默认中文字体)
35.6MB/简体中文/1.4详情
羿创无厘头爱体字体 免费版
1.29MB/简体中文/8.1详情
方正颜宋字体
12.2MB/简体中文/3.6详情
helveticaneue字体
1.73MB/简体中文/2.7详情
华文新魏字体下载
2.56MB/简体中文/6.8详情
方正大黑简体
1.18MB/简体中文/5.5详情
微软雅黑字体
16MB/简体中文/5.5详情
思源黑体
43.7MB/简体中文/3.8详情
方正静蕾简体字体 徐静蕾的手写字体
3.07MB/简体中文/3.2详情
方正兰亭黑简体
26.2MB/简体中文/5.3详情
